Concepts
sq
sq is the command-line utility itself. It is free/libre open-source software, available
under the MIT License. The code is
available on GitHub. sq was created
by Neil O’Toole.
SLQ
SLQ is the formal name of sq’s query language, similar to
jq’s syntax. The Antlr grammar
is available on GitHub.
Ultimately, SLQ is transpiled to SQL, which is executed against the target
data source.
--render-sql to preview the SQL.Source
A source is a data source such as a database instance (SQL source), or an Excel or CSV file (document source). A source has a driver type, location and handle.
Learn more in the sources section.
Driver type
This is the driver type used to connect to the source,
e.g. postgres, sqlserver, clickhouse, csv, etc. You can specify the type explicitly
when invoking sq add, but usually sq can detect
the driver automatically.
Location
The source location is the URI or file path of the source, such
as postgres://sakila:****@localhost/sakila
or /Users/neilotoole/sq/xl_demo.xlsx. You specify the source location when
invoking sq add.
Handle
The handle is how sq refers to a data source, such as @sakila or @customer_csv.
The handle must begin with @. You specify the handle when adding a source with sq add.
The handle can also be used to specify a source group, e.g. @prod/sales, @dev/sales.
Active source
The active source is the source upon which sq acts if no other source is specified.
By default, sq requires that the first element of a query is the source handle:
$ sq '@sakila | .actor | .first_name, last_name'
But if an active source is set, you can omit the handle:
$ sq '.actor | .first_name, .last_name'
You can use sq src to get or set the active source.
SQL source
A SQL source is a source backed by a “real” DB, such as Postgres. Contrast with document source.
Document source
A document source is a source backed by a document or file
such as CSV or XLSX. Some functionality
is not available for document sources. For example, sq doesn’t provide a mechanism to insert query
results into a CSV file. Contrast with SQL source. A document source’s data
is automatically ingested by sq. The document source’s location
can be a local filepath or an HTTP URL.
Group
The group mechanism organizes sources into groups, based on path-like names.
Given handles @prod/sales, @dev/sales and @dev/test, we have three
sources, but two groups, prod and dev. See the groups docs.
Active group
Like active source, there is an active group. Use
the sq group command to get or set the active group.
Driver
A driver is a software component implemented by sq for each data source type. For
example, Postgres or CSV.
Use sq driver ls to view the available drivers.
Monotable
If a source is monotable, it means that the source type is really only a single table, such
as a CSV file. sq always names that single table data. You access that
table
like this: @actor_csv | .data.
Note that not all document sources are monotable. For example, XLSX sources have multiple tables, where each worksheet is effectively equivalent to a DB table.
Metadata
sq inspect returns metadata about a source. At a minimum, sq inspect
is useful for a quick reminder of table and column names:
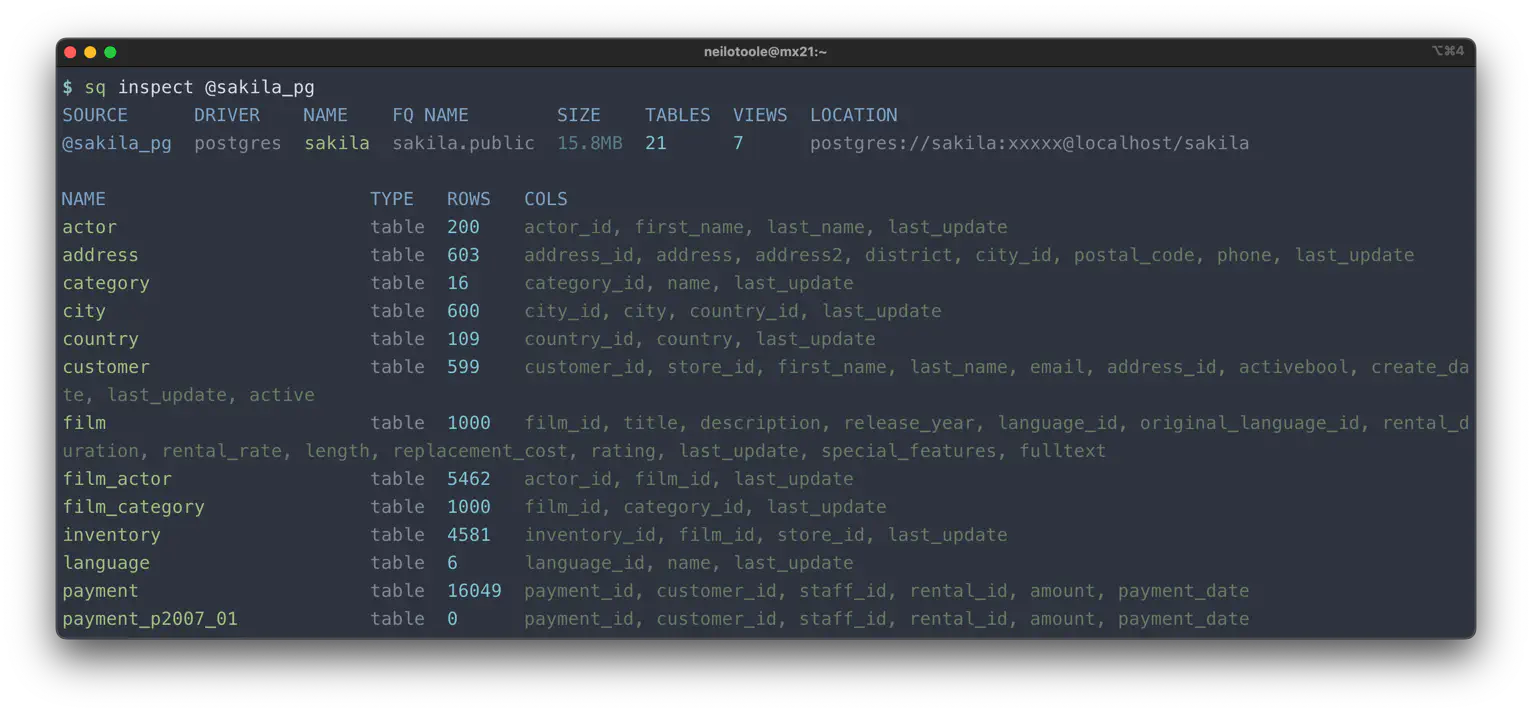
sq inspect comes into its own when used with the --json flag, which outputs voluminous info
on the data source. It is a frequent practice to combine sq inspect
with jq.
For example, to list the tables of the active source:
$ sq inspect -j | jq -r '.tables[] | .name'
actor
address
category
[...]
See more examples in the cookbook.
Ingest DB
Ingest DB refers to the temporary ("ingest") database that sq uses for under-the-hood
activity such as converting a document source like CSV to relational
format. By default, sq uses an embedded SQLite instance for the ingest DB.
Join DB
Join DB is similar to Ingest DB, but is used for cross-source joins. By default, sq
uses an embedded SQLite instance for the Join DB.
Schema & catalog
Database implementations have the concept of a schema, which you can think of as a namespace for tables. Some databases go further and support the concept of a catalog, which is a collection of schemas. Often the terms catalog and database are used interchangeably, and, in practice, the various terms are used inconsistently and confusedly.
sq doesn’t concern itself
with clusters.Here’s what the hierarchy looks like for Postgres (credit):
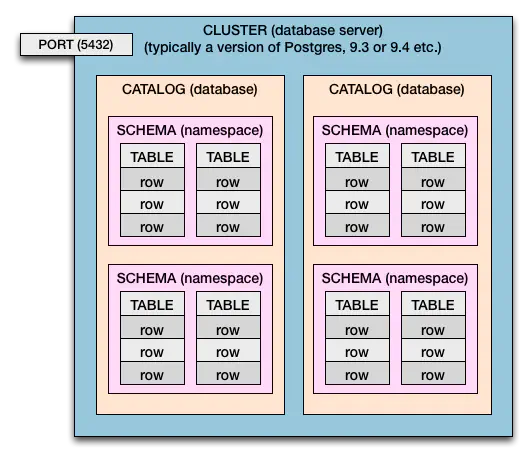
Each of the sq DB driver implementations supports the concept of a schema in some way,
but some drivers don’t support the catalog mechanism. Here’s a summary:
| Driver | Default schema | Catalog support? |
|---|---|---|
| Postgres | public | Yes |
| SQLite | main | No |
| MySQL | Connection-dependent | No |
| SQL server | dbo | Yes |
| ClickHouse | default | Yes |
| Oracle | Connected user | Read-only (catalog() returns the PDB / DB_NAME; not switchable at runtime — reconnect via a different service name) |
The SLQ functions schema() and catalog() return
the schema and catalog of the active source. See the docs for details of how each driver implements
these functions.