Config
sq aims to work out of the box with sane defaults, but allows you to configure most
everything. sq’s total configuration state consists of a collection of
data sources and groups, and a plethora
of configuration options. That’s what this section is about. There are two levels
of options:
- Base config, consisting of many options. Each option is a key-value pair,
e.g.
format=json, orconn.max-open=50 - Source-specific config. Each source can have its own value for, say,
conn.max-open. If an option is not explicitly set on a source, the source inherits that option value from base config.
Commands
sq provides commands to locate, list, get,
set, and edit config. The config commands provide extensive
shell-completion, so feel free to hit TAB while
entering a command, and sq will guide you.
location
sq stores its main config in a sq.yml file in its config dir. You don’t usually
need to edit the config directly: sq provides several mechanisms for managing config.
The location of sq's config dir is OS-dependent. On macOS, it’s here:
$ sq config location
/Users/neilotoole/.config/sq
You can specify an alternate location by setting envar SQ_CONFIG:
$ export SQ_CONFIG=/tmp/sq
$ sq config location
/tmp/sq
You can also specify the config dir via the --config flag:
$ sq --config=/tmp/sq2 config location
/tmp/sq2
ls
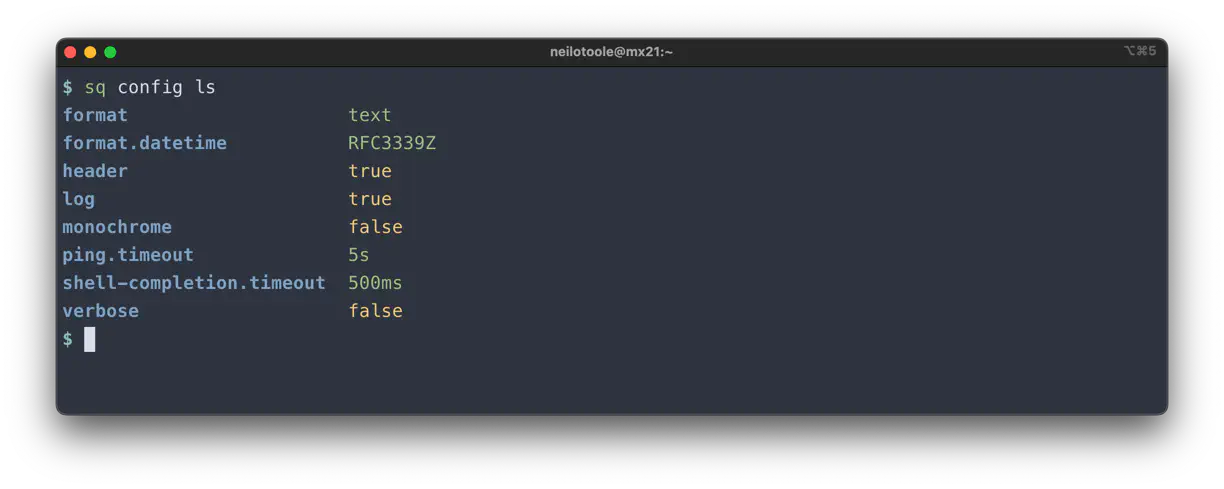
Use sq config ls to list the options that have been set.
# List config options
$ sq config ls
Well, there’s more. A lot more. Use sq config ls -v to also see unset options,
along with their default values.
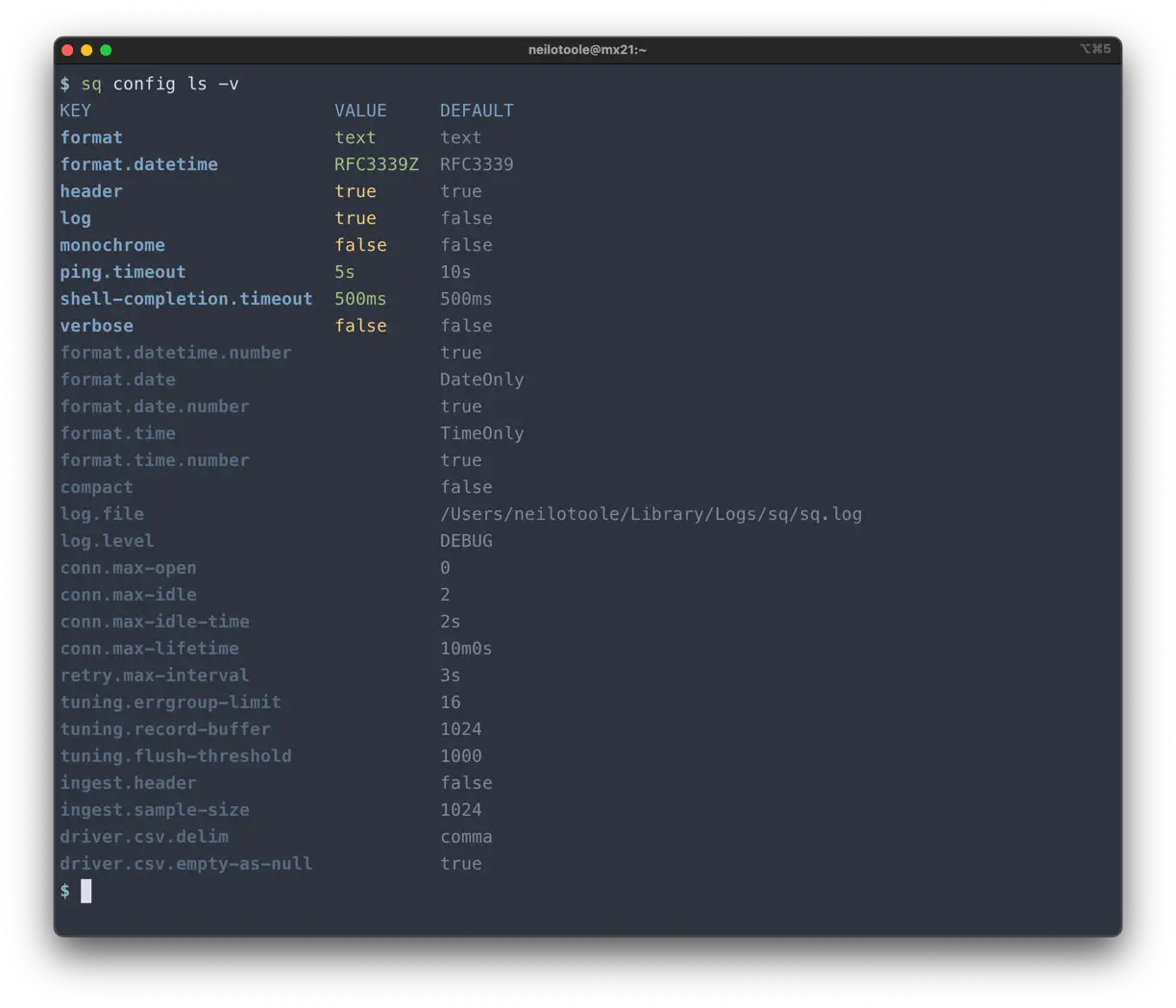
Note in the image above that some options don’t have a value. That is to say, the option is unset. When unset, an option takes on its default value.
sq config ls -yv (the -y flag is for
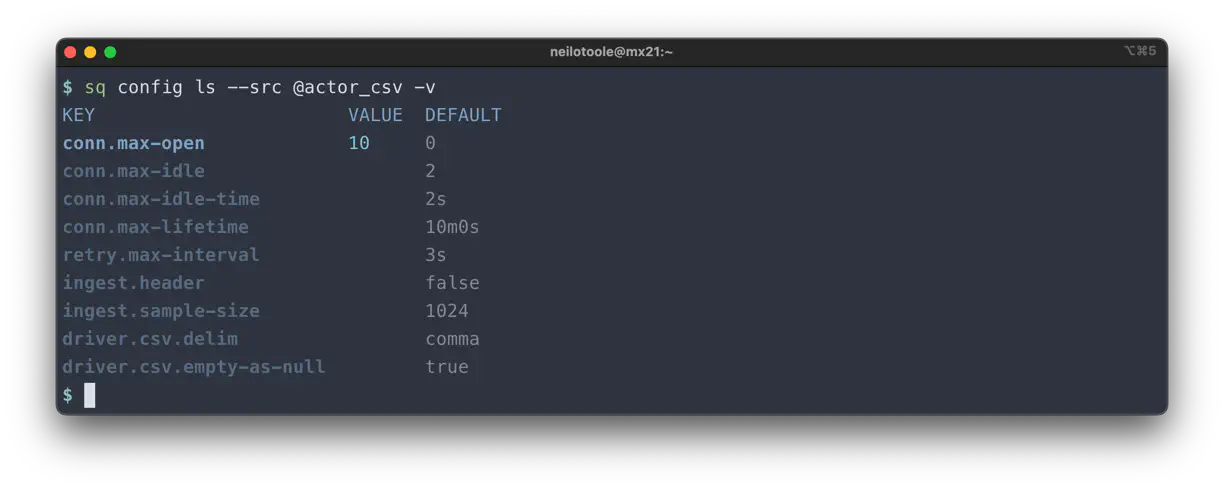
--yaml output). That’s the maximum amount of detail available.As well as listing base config, you can view config options for a source.
$ sq config ls --src @actor_csv -v
get
sq config get is like the single-friend counterpart of sq ls. It gets the
value of a single option.
# Get base value of "format" option
$ sq config get format
text
# Get the "conn.max-open" option value for a particular source
$ sq config get --src @actor_csv conn.max-open
10
set
Use sq config set or sq config set --src to set an option value.
# Set base option value
$ sq config set format json
# Set source-specific option value
$ sq config set --src @sakila_pg conn.max-open 20
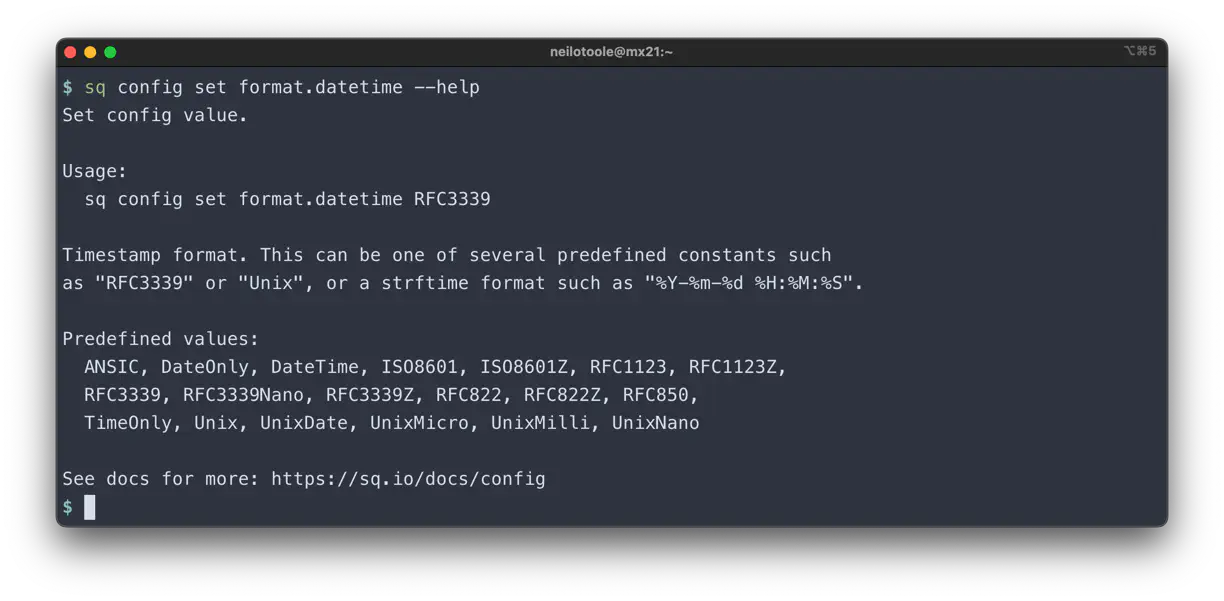
To get help for a specific option, execute sq config set OPTION --help.
edit
In the spirit of
kubectl edit,
you can edit base config or source-specific config via the
default editor, as defined in envar $EDITOR or $SQ_EDITOR.
# Edit base config
$ sq config edit
# Edit config for source
$ sq config edit @sakila
# Use a different editor
$ SQ_EDITOR=nano sq config edit
If you add the -v flag (sq config edit -v), the editor will show
additional help for the options.
Upgrades
When a new sq version changes the config schema, sq migrates sq.yml
automatically on first run. Before migrating, sq writes a verbatim backup of
the config to the same dir, named for the version being upgraded from, e.g.
sq.v0.53.0.bak.yml. sq never reads, modifies, or deletes the backup: it
exists solely so you can restore the previous config if needed.
The backup is created with user-only file permissions, but it preserves the
old config exactly, including any inline credentials. If you later move your
credentials out of the config (e.g. via
sq config keyring migrate), remember
that the backup still holds the plaintext values; delete it when you no
longer need it.
Logging
By default, logging is turned off. If you need to submit a sq
bug report, you’ll likely
want to include the sq log file.
# Enable logging
$ sq config set log true
# Default log level is DEBUG... you can change it if you want.
# But leave it on DEBUG if you're sending bug reports.
$ sq config set log.level WARN
# The default log format is "text", a human-friendly format. You can
# also change it to "json" if you prefer.
$ sq config set log.format json
# You can also change the log file location.
$ sq config set log.file /tmp/sq.log
# Note that the default log file location is OS-dependent.
$ sq config get log.file -v
KEY VALUE DEFAULT
log.file /Users/neilotoole/Library/Logs/sq/sq.log
# To output just the log file path:
$ sq config get log.file -jv | jq -r .value
/Users/neilotoole/Library/Logs/sq/sq.log
If there’s a problem with sq’s bootstrap mechanism (e.g. corrupt config file),
and logs aren’t being generated, you can use envars to force logging,
overriding the config file. For example:
export SQ_LOG=true; export SQ_LOG_LEVEL=DEBUG; export SQ_LOG_FORMAT=text; export SQ_LOG_FILE=./sq.log
Options
Below, all available options are listed. Use sq config set OPTION to
modify the option value.
Some config options apply only to base config. For example, format=json applies
to the sq CLI itself, and not to a particular source such as @sakila. However,
some options can apply to a source, and also have a base value. For example,
conn.max-open controls the maximum number of connections that sq will open
to a database. This option can be set for base config, but can also be set for
an individual source, overriding the base config.
CLI
log
Usage:
sq config set log false
Enable logging.
log.file
Usage:
sq config set log.file $HOME/Library/Logs/sq/sq.log
Path to log file. Empty value disables logging.
log.format
Usage:
sq config set log.format text
Log output format. Allowed formats are "text" (human-friendly) or "json".
log.level
Usage:
sq config set log.level DEBUG
Log level, one of: DEBUG, INFO, WARN, ERROR.
error.format
Usage:
sq config set error.format text
The format to output errors in. Allowed formats are "text" or "json".
error.stack
Usage:
sq config set error.stack false
Print error stack trace to stderr. This only applies when error.format is
"text"; when error.format is "json", the stack trace is always printed.
error.format.text.verbose
Usage:
sq config set error.format.text.verbose true
When true (default), syntax errors shown in "text" error format include the
full report: the offending span highlighted in the original query, plus any
"did you mean" suggestion. When false, only the first summary line is shown
(e.g. "sq: syntax error at line 1, col 10: unexpected 'mx'").
This only applies when error.format is "text"; "json" error output always
includes the full structured parse_error.
ping.timeout
Usage:
sq config set ping.timeout 10s
How long the ping command waits before timeout occurs. Example: 500ms or 2m10s.
http.request.timeout
Usage:
sq config set http.request.timeout 10s
How long to wait for initial response from a HTTP/S endpoint before timeout
occurs. Reading the body of the response, such as a large HTTP file download,
is not affected by this option. Example: 500ms or 3s.
Contrast with http.response.timeout.
http.response.timeout
Usage:
sq config set http.response.timeout 0s
How long to wait for the entire HTTP transaction to complete. This includes
reading the body of the response, such as a large HTTP file download. Typically
this is set to 0, indicating no timeout.
Contrast with http.request.timeout.
https.insecure-skip-verify
Usage:
sq config set https.insecure-skip-verify false
Skip HTTPS TLS verification. Useful when downloading against self-signed certs.
download.cache
Usage:
sq config set download.cache true
Cache downloaded remote files. When false, the download cache is not used and
the file is re-downloaded on each command.
download.refresh.ok-on-err
Usage:
sq config set download.refresh.ok-on-err true
Continue with stale download if refresh fails. This option applies if a download
is in the cache, but is considered stale, and a refresh attempt fails. If set to
true, the refresh error is logged, and the stale download is returned. This is a
sort of "Airplane Mode" for downloads: when true, sq continues with the cached
download when the network is unavailable. If false, an error is returned instead.
progress
Usage:
sq config set progress true
Show progress bar for long-running operations.
progress.delay
Usage:
sq config set progress.delay 2s
Delay before showing a progress bar.
progress.max-bars
Usage:
sq config set progress.max-bars 5
Limit the number of progress bars shown concurrently in the terminal. When the
threshold is reached, further progress bars are grouped into a single group bar.
If zero, no progress bar is rendered.
shell-completion.timeout
Usage:
sq config set shell-completion.timeout 500ms
How long shell completion should wait before giving up. This can become relevant
when shell completion inspects a source's metadata, e.g. to offer a list of
tables in a source.
shell-completion.group-filter
Usage:
sq config set shell-completion.group-filter true
When true, shell completion initially suggests only sources within the active
group. When false, all sources are suggested. However, note that if the user
continues to input a source handle that is outside the active group, completion
will suggest all matching sources, regardless of this option's value.
shell-completion.log
Usage:
sq config set shell-completion.log false
Enable logging of shell completion activity. This is really only useful for
debugging shell completion functionality. It's disabled by default, because it's
frequently the case that shell completion handlers will trigger work (such as
inspecting the schema) that doesn't complete by the shell completion timeout.
This can result in the logs being filled with uninteresting junk when the
timeout triggers logging of errors.
config.lock.timeout
Usage:
sq config set config.lock.timeout 5s
Wait timeout to acquire the config lock (which prevents multiple sq instances
stepping on each other's config changes). During this period, retry will occur
if the lock is already held by another process. If zero, no retry occurs.
Output
compact
Usage:
sq config set compact false
Compact instead of pretty-printed output.
format
Usage:
sq config set format text
Specify the output format. Some formats are only implemented for a subset of
sq's commands. If the specified format is not available for a particular
command, sq falls back to "text". Available formats:
text, csv, tsv, xlsx,
json, jsona, jsonl,
markdown, html, xlsx, xml, yaml, raw
format.datetime
Usage:
sq config set format.datetime RFC3339
Timestamp format. This can be one of several predefined constants such as
"RFC3339" or "Unix", or a strftime format such as "%Y-%m-%d %H:%M:%S".
Predefined values:
ANSIC, DateOnly, DateTime, ISO8601, ISO8601Z, RFC1123, RFC1123Z,
RFC3339, RFC3339Nano, RFC3339Z, RFC822, RFC822Z, RFC850,
TimeOnly, Unix, UnixDate, UnixMicro, UnixMilli, UnixNano
format.datetime.number
Usage:
sq config set format.datetime.number true
Render numeric datetime value as number instead of string, if possible. If
format.datetime renders a numeric value (e.g. a Unix timestamp such as
"1591843854"), that value is typically rendered as a string. For some output
formats, such as JSON, it can be useful to instead render the value as a naked
number instead of a string. Note that this option is no-op if the rendered value
is not an integer.
format.datetime.number=false
[{"first_name":"PENELOPE","last_update":"1591843854"}]
format.datetime.number=true
[{"first_name":"PENELOPE","last_update":1591843854}]
format.date
Usage:
sq config set format.date DateOnly
Date format. This can be one of several predefined constants such as "DateOnly"
or "Unix", or a strftime format such as "%Y-%m-%d". Note that date values are
sometimes programmatically indistinguishable from datetime values. In that
situation, use format.datetime instead.
Predefined values:
ANSIC, DateOnly, DateTime, ISO8601, ISO8601Z, RFC1123, RFC1123Z,
RFC3339, RFC3339Nano, RFC3339Z, RFC822, RFC822Z, RFC850,
TimeOnly, Unix, UnixDate, UnixMicro, UnixMilli, UnixNano
format.date.number
Usage:
sq config set format.date.number true
Render numeric date value as number instead of string, if possible. If
format.date renders a numeric value (e.g. a year such as "1979"), that value is
typically rendered as a string. For some output formats, such as JSON, it can be
useful to instead render the value as a naked number instead of a string. Note
that this option is no-op if the rendered value is not an integer.
format.date.number=false
[{"first_name":"PENELOPE","birth_year":"1979"}]
format.date.number=true
[{"first_name":"PENELOPE","birth_year":1979}]
format.time
Usage:
sq config set format.time TimeOnly
Time format. This can be one of several predefined constants such as "TimeOnly"
or "Unix", or a strftime format such as "%Y-%m-%d". Note that time values are
sometimes programmatically indistinguishable from datetime values. In that
situation, use format.datetime instead.
Predefined values:
ANSIC, DateOnly, DateTime, ISO8601, ISO8601Z, RFC1123, RFC1123Z,
RFC3339, RFC3339Nano, RFC3339Z, RFC822, RFC822Z, RFC850,
TimeOnly, Unix, UnixDate, UnixMicro, UnixMilli, UnixNano
format.time.number
Usage:
sq config set format.time.number true
Render numeric time value as number instead of string, if possible. If format.time
renders a numeric value (e.g. "59"), that value is typically rendered as a string.
For some output formats, such as JSON, it can be useful to instead render the
value as a naked number instead of a string. Note that this option is no-op if
the rendered value is not an integer.
format.time.number=false
[{"first_name":"PENELOPE","favorite_minute":"59"}]
format.time.number=true
[{"first_name":"PENELOPE","favorite_minute":59}]
format.excel.datetime
Usage:
sq config set format.excel.datetime 'yyyy-mm-dd hh:mm'
Timestamp format for datetime values: that is, for values that have both a date
and time component. The exact format is specific to Microsoft Excel, but is
broadly similar to strftime.
Examples:
"yyyy-mm-dd hh:mm" 1989-11-09 16:07
"dd/mm/yy h:mm am/pm" 09/11/89 4:07 pm
"dd-mmm-yy h:mm:ss AM/PM" 09-Nov-89 4:07:01 PM
See also: Excel date/time format reference
format.excel.date
Usage:
sq config set format.excel.date yyyy-mm-dd
Date format string for Microsoft Excel date-only values. The exact format is
specific to Excel, but is broadly similar to strftime.
Examples:
"yyyy-mm-dd" 1989-11-09
"dd/mm/yy" 09/11/89
"dd-mmm-yy" 09-Nov-89
See also: Excel date/time format reference
format.excel.time
Usage:
sq config set format.excel.time hh:mm:ss
Time format string for Microsoft Excel time-only values. The exact format is
specific to Excel, but is broadly similar to strftime.
Examples:
"hh:mm:ss" 16:07:10
"h:mm am/pm" 4:07 pm
"h:mm:ss AM/PM" 4:07:01 PM
Note that time-only values are sometimes programmatically indistinguishable from
datetime values. In that situation, use format.excel.datetime instead.
See also: Excel date/time format reference
format.html.embed-assets
Usage:
sq config set format.html.embed-assets false
When true, sq inspect's HTML output inlines all assets — notably the
Mermaid.js library — so the document is fully self-contained and renders
offline. When false (default), Mermaid.js is loaded from a CDN, producing a
much smaller file that requires internet access to render the diagram.
This option applies to sq inspect’s HTML output. As with
other options, it can be set per invocation via the matching
--format.html.embed-assets flag.
header
Usage:
sq config set header true
Controls whether a header row is printed. This applies only to certain formats,
such as "text" or "csv".
monochrome
Usage:
sq config set monochrome false
Don't print color output.
See Output modifiers: monochrome and environment variables
for how --monochrome interacts with NO_COLOR, FORCE_COLOR, and terminal
detection.
verbose
Usage:
sq config set verbose false
Print verbose output.
secrets.reveal
Controls whether sensitive fields (passwords in source locations, stored
keyring values) are printed verbatim or redacted in output. Default is
false: secrets are redacted.
# Default behavior: password is redacted.
$ sq src -v
@sakila/pg12 postgres postgres://sakila:xxxxx@192.168.50.132/sakila
# Set secrets.reveal to true.
$ sq config set secrets.reveal true
# Now the password is visible.
$ sq src -v
@sakila/pg12 postgres postgres://sakila:p_ssW0rd@192.168.50.132/sakila
secrets.reveal is the persistent form of the global
--reveal flag. The earlier --no-redact
flag still works but is deprecated; use --reveal in new scripts.
See Secrets for the full picture, including how --reveal
relates to sq config export --expand and the
placeholder system.
redact option (default true) was
renamed to secrets.reveal (default false) for polarity-consistency with
the --reveal flag. Existing configs migrate automatically on first run.
Scripts that call sq config get redact or sq config set redact ...
need updating to the new key.Usage:
sq config set secrets.reveal false
Show secret values in output. When true, passwords in source
locations and stored keyring values are printed verbatim; when false
(the default), they are redacted in output that prints a location or
keyring value.
This is the persistent form of the global --reveal flag.
secrets.store
Default storage backend used by sq add when the source URL
carries a password: inline (write the URL verbatim into sq.yml, the
historical default) or keyring (write the full conn string to the OS keyring at a
fresh opaque ID and store a bare ${keyring:<id>} placeholder in YAML).
# Make keyring the default for new sources
$ sq config set secrets.store keyring
The --store flag on sq add overrides this option per invocation. See
Secrets for the keyring scheme and the
threat model.
Usage:
sq config set secrets.store inline
Default secret storage backend used by "sq add" when the source URL
carries a password.
inline Store the URL verbatim in the YAML config (password and all).
Historical default.
keyring Write the full DSN to the OS keyring at a fresh opaque ID
and store a bare "${keyring:<id>}" placeholder as the YAML
Location. The keyring entry holds the entire DSN; only the
opaque ID lands in YAML.
The --store flag on sq add overrides this setting per invocation.
result.column.rename
Usage:
sq config set result.column.rename '{{.Name}}{{with .Recurrence}}_{{.}}{{end}}'
This Go text template is executed on the column names returned from the DB. Its
primary purpose is to rename duplicate column names. For example, given a query
that results in this SQL:
SELECT * FROM actor JOIN film_actor ON actor.actor_id = film_actor.actor_id
The returned result set will have these column names:
actor_id, first_name, last_name, last_update, actor_id, film_id, last_update
|- from "actor" -| |- from "film_actor" -|
Note the duplicate "actor_id" and "last_update" column names. When output in a
format (such as JSON) that doesn't permit duplicate keys, only one of each
duplicate column could appear.
The fields available in the template are:
.Name column name
.Index zero-based index of the column in the result set
.Alpha alphabetical index of the column, i.e. [A, B ... Z, AA, AB]
.Recurrence nth recurrence of the colum name in the result set
For a unique column name, e.g. "first_name" above, ".Recurrence" will be 0. For
duplicate column names, ".Recurrence" will be 0 for the first instance, then 1
for the next instance, and so on.
Note that this option only applies when the result set contains duplicates. To
rename result columns generally, use a column alias. Note also that this option
applies globally; it cannot be set on a per-source basis. This is because it's
ambiguous what would happen on a join where each source had a different renaming
template.
The default template renames the columns to:
actor_id, first_name, last_name, last_update, actor_id_1, film_id, last_update_1
The result.column.rename option is rather arcane: it allows you to change
the way sq de-duplicates column names. By default, a result set containing
duplicate column names is renamed like this:
-- Columns returned from DB...
actor_id, first_name, last_name, last_update, actor_id, film_id, last_update
-- are renamed to
actor_id, first_name, last_name, last_update, actor_id_1, film_id, last_update_1
Thus, the second actor_id column becomes actor_id_1. Let’s say you instead
wanted the column to be renamed to actor_id:1. Change the template value to
use : instead of _.
$ sq config set result.column.rename '{{.Name}}{{with .Recurrence}}:{{.}}{{end}}'
The option value must be a valid Go text template.
In addition to the standard Go functions, the sprig
functions are available. Here’s an example of a template using the sprig upper function to
rename each column to uppercase.
{{.Name | upper}}{{with .Recurrence}}:{{.}}{{end}}
The .Alpha template field maps the column index to A, B ... Y, Z, AA, AB...,
similar to how Microsoft Excel names columns. To use this style:
$ sq config set result.column.rename '{{.Alpha}}'
$ sq .actor
ingest.column.rename and
result.column.rename are distinct options.
The ingest option is applied to ingest data (e.g. a CSV file) column names
before the data is sent to the database (pre-processing).
The result option, by contrast, is applied
to result set column names after the data is returned from the database (post-processing).
It is possible (and normal) to use both options.diff.data.format
Usage:
sq config set diff.data.format text
Specify the output format to use when comparing table data.
Available formats:
text, csv, tsv,
json, jsona, jsonl,
markdown, html, xml, yaml
diff.lines
Configures the number of context lines that sq diff shows before and after
a difference. You can use the --unified (-U) flag, e.g.:
$ sq diff @prod/sales.payments @staging/sales.payments -U4
Usage:
sq config set diff.lines 3
Generate diffs with <n> lines of context, where n >= 0.
diff.stop
Configures the default stop-after value for sq diff.
You can use the --stop (-n) flag, e.g.:
$ sq diff @prod/sales.payments @staging/sales.payments -n10
Note that diff.stop only applies to table row data diffs, not to metadata diffs.
Usage:
sq config set diff.stop 3
Stop after <n> differences are found. If n <= 0, no limit is applied.
diff.max-hunk-size
Usage:
sq config set diff.max-hunk-size 5000
Maximum size of individual diff hunks. A hunk is a segment of a diff that
contains differing lines, as well as non-differing context lines before and
after the difference. A hunk must be loaded into memory in its entirety; this
setting prevents excessive memory usage. If a hunk would exceed this limit, it
is split into multiple hunks; this still produces a well-formed diff.
Tuning
conn.max-idle
Usage:
sq config set conn.max-idle 2
Set the maximum number of connections in the idle connection pool. If
conn.max-open is greater than 0 but less than the new conn.max-idle, then the
new conn.max-idle will be reduced to match the conn.max-open limit.
If n <= 0, no idle connections are retained.
conn.max-idle-time
Usage:
sq config set conn.max-idle-time 2s
Sets the maximum amount of time a connection may be idle. Expired connections
may be closed lazily before reuse.
If n <= 0, connections are not closed due to a connection's idle time.
conn.max-lifetime
Usage:
sq config set conn.max-lifetime 10m0s
Set the maximum amount of time a connection may be reused. Expired connections
may be closed lazily before reuse.
If n <= 0, connections are not closed due to a connection's age.
conn.max-open
Usage:
sq config set conn.max-open 0
Maximum number of open connections to the database.
A value of zero indicates no limit.
conn.open-timeout
Usage:
sq config set conn.open-timeout 10s
Max time to wait before a connection open timeout occurs.
retry.max-interval
Usage:
sq config set retry.max-interval 3s
The maximum interval to wait between retries. If an operation is
retryable (for example, if the DB has too many clients), repeated retry
operations back off, typically using a Fibonacci backoff.
tuning.errgroup-limit
Usage:
sq config set tuning.errgroup-limit 16
Controls the maximum number of goroutines that can be spawned by an errgroup.
Note that this is the limit for any one errgroup, but not a ceiling on the total
number of goroutines spawned, as some errgroups may themselves start an
errgroup.
This knob is primarily for internal use. Ultimately it should go away in favor
of dynamic errgroup limit setting based on availability of additional DB conns,
etc.
tuning.output-flush-threshold
Usage:
sq config set tuning.output-flush-threshold 1000B
Size after which output writers should flush any internal buffer.
Generally, it is not necessary to fiddle this knob.
Use units B, KB, MB, GB, etc. For example, 64KB, or 10MB. If no unit specified,
bytes are assumed.
tuning.record-buffer
Usage:
sq config set tuning.record-buffer 1024
Controls the size of the channel for buffering records.
tuning.buffer-spill-limit
Usage:
sq config set tuning.buffer-spill-limit 1MB
Size after which in-memory temp buffers spill to disk.
Use units B, KB, MB, GB, etc. For example, 64KB, or 10MB. If no unit specified,
bytes are assumed.
tuning.scan-buffer-limit
Usage:
sq config set tuning.scan-buffer-limit 32MB
Maximum size of the buffer used for scanning tokens. The buffer will start
small and grow as needed, but will not exceed this limit.
Use units B, KB, MB, GB, etc. For example, 64KB, or 10MB. If no unit specified,
bytes are assumed.
Ingest
ingest.cache
Enable or disable the ingest cache. You can also use the
sq cache enable and sq cache disable
commands.
Usage:
sq config set ingest.cache true
Specifies whether ingested data is cached or not, on a default or per-source
basis. When data is ingested from a document source, it is stored in a cache DB.
Subsequent uses of that same source will use that cached DB instead of ingesting
the data again, unless this option is set to false, in which case, the data is
ingested each time.
# Set default ingest caching behavior
$ sq config set ingest.cache false
# Set ingest caching behavior for a specific source
$ sq config set --src @sakila ingest.cache false
cache.lock.timeout
Usage:
sq config set cache.lock.timeout 5s
Wait timeout to acquire cache lock. During this period, retry will occur
if the lock is already held by another process. If zero, no retry occurs.
ingest.column.rename
Usage:
sq config set ingest.column.rename '{{.Name}}{{with .Recurrence}}_{{.}}{{end}}'
This Go text template is executed on ingested column names.
Its primary purpose is to rename duplicate header column names in the
ingested data. For example, given a CSV file with header row:
actor_id, first_name, actor_id
The default template renames the columns to:
actor_id, first_name, actor_id_1
The fields available in the template are:
.Name column header name
.Index zero-based index of the column in the header row
.Alpha alphabetical index of the column, e.g. [A, B ... Z, AA, AB]
.Recurrence nth recurrence of the colum name in the header row
For a unique column name, e.g. "first_name" above, ".Recurrence" will be 0.
For duplicate column names, ".Recurrence" will be 0 for the first instance,
then 1 for the next instance, and so on.
ingest.column.rename and
result.column.rename are distinct options.
The ingest option is applied to ingest data (e.g. a CSV file) column names
before the data is sent to the database (pre-processing).
The result option, by contrast, is applied
to result set column names after the data is returned from the database (post-processing).
It is possible (and normal) to use both options.ingest.header
Usage:
sq config set ingest.header false
Specifies whether ingested data has a header row or not.
If not set, the ingester *may* try to detect if the input has a header.
Generally it is best to leave this option unset and allow the ingester
to detect the header.
ingest.sample-size
Usage:
sq config set ingest.sample-size 256
Specify the number of samples that a detector should take to determine type.
driver.csv.delim
Usage:
sq config set driver.csv.delim comma
Delimiter to use for CSV files. Default is "comma".
Possible values are: comma, space, pipe, tab, colon, semi, period.
driver.csv.empty-as-null
Usage:
sq config set driver.csv.empty-as-null true
When true, empty CSV fields are treated as NULL. When false,
the zero value for that type is used, e.g. empty string or 0.