Sources
A source is an individual data source, such as a database connection, or a CSV or Excel document.
Overview
A source has three main elements:
- driver: a driver type such as
postgres, orcsv. - handle: such as
@sakila_pg. A handle always starts with@. The handle is used to refer to the data source. A handle can also specify a group, e.g.@prod/sakila. - location: such as
postgres://user:p_ssW0rd@localhost/sakila. For a document source, location may just be a file path, e.g./Users/neilotoole/sakila.csv.
When sq prints a location containing security credentials (such as the password in the
postgres string above), the password is redacted by default. Thus, that location string
would be printed as postgres://user:xxxxx@@localhost/sakila.
You can override this behavior via the global --no-redact flag, or by setting
the redact config option to false,
sq provides a set of commands to add, list, rename
and remove sources.
Add
To add a source, use sq add. The command packs in a lot of functionality:
see the docs for detail.
# Add a postgres database
$ sq add postgres://sakila:p_ssW0rd@localhost/sakila
@sakila_pg postgres sakila@localhost/sakila
# Add a CSV source, specifying the handle.
$ sq add ./actor.csv --handle @actor
Location completion
It can be difficult to remember the format of database URLs (i.e. the source location).
To make life easier, sq provides shell completion for the sq add LOCATION field. To
use it, just press TAB after $ sq add.
For location completion to work, do not enclose the location in single quotes. However,
this does mean that the inputted location string must escape special shell characters
such as ? and &.
# Location completion not available, because location is in quotes.
$ sq add 'postgres://sakila@192.168.50.132/sakila?sslmode=disable'
# Location completion available: note the escaped ?.
$ sq add postgres://sakila@192.168.50.132/sakila\?sslmode=disable
The location completion mechanism suggests usernames, hostnames (from history),
database names, and even values for query params (e.g. ?sslmode=disable) for
each supported database. It never suggests passwords.
List sources
Use sq ls to list sources.
$ sq ls
@dev/customer csv customer.csv
@dev/sales csv sales.csv
@prod/customer csv customer.csv
@prod/sales csv sales.csv
In practice, colorization makes things a little easier to parse.
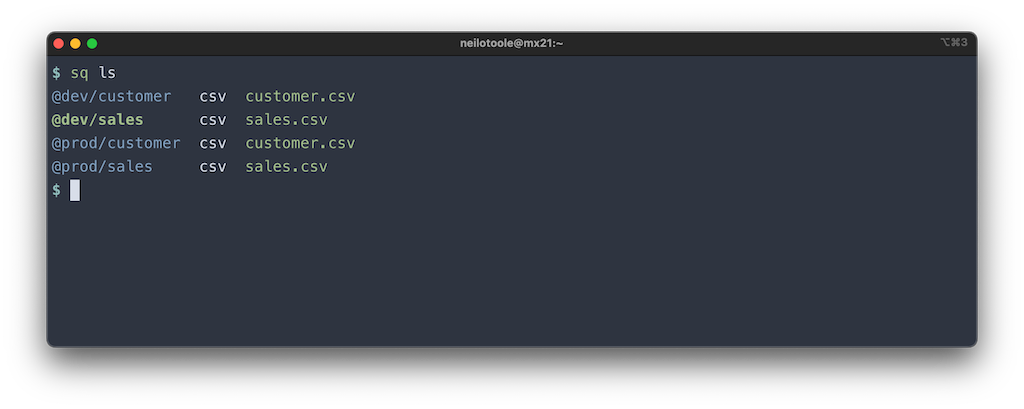
Note that the @dev/sales source is highlighted. This means that it’s
the active source (you can get the active source
at any time via sq src).
Pass the -v (--verbose) flag to see more detail:
$ sq ls -v
HANDLE ACTIVE DRIVER LOCATION OPTIONS
@dev/customer csv /Users/neilotoole/sakila-csv/customer.csv
@dev/sales active csv /Users/neilotoole/sakila-csv/sales.csv
@prod/customer csv /Users/neilotoole/sakila-csv/customer.csv
@prod/sales csv /Users/neilotoole/sakila-csv/sales.csv
sq ls operates on the active group. By default, this is the / root group.
So, when the default group is /, then sq ls is equivalent to sq ls /.
But just like the UNIX ls command, you can supply an argument to sq ls to
list the sources in that group.
# List sources in the "prod" group.
$ sq ls prod
@prod/customer csv customer.csv
@prod/sales csv sales.csv
List groups
Use sq ls -g (--group) to list groups instead of sources.
$ sq ls -g
/
dev
prod
See more detail by adding -v:
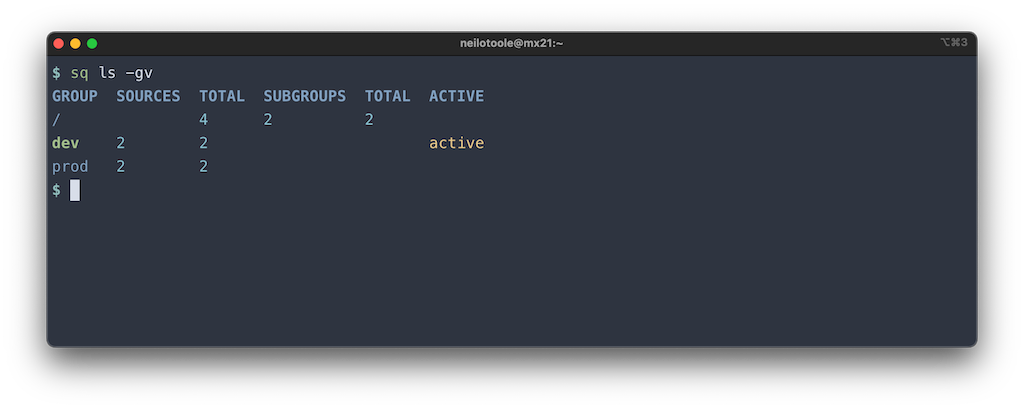
Like the plain sq ls command, you can pass an argument to ls -g to
see just the subgroups of the argument.
$ sq ls -gv prod
GROUP SOURCES TOTAL SUBGROUPS TOTAL ACTIVE
prod 2 2
Active source
The active source is the source upon which sq acts if no other source is specified.
By default, sq requires that the first element of a query be the source handle:
$ sq '@sakila | .actor | .first_name, last_name'
But if an active source is set, you can omit the handle:
$ sq '.actor | .first_name, .last_name'
Use sq src to get or set the active source.
# Get active source
$ sq src
@sakila_sl3 sqlite3 sakila.db
# Set active source
$ sq src @sakila_pg12
@sakila_pg12 postgres sakila@192.168.50.132/sakila
If no active source is set (like when you first start using sq), and
you sq add a source, that source becomes the active source.
When you sq rm the active source, there will no longer be an active source.
Like the active source, there is an active group. Use
the equivalent sq group command to get or set the active group.
Source override
Many commands accept a specific source handle as an argument. For example:
# Inspect the @sakila_pg source
$ sq inspect @sakila_pg
When that source handle is omitted, sq uses the active source.
# Inspect the active source
$ sq inspect
However, some commands (for ergonomic reasons) don’t accept a source handle as an argument.
# Execute SQL query against the active source
$ sq sql 'SELECT * FROM actor'
For these commands, you can generally use the --src flag to override the active source
for just that single command invocation.
# Execute SQL query against the @sakila_pg source
$ sq sql 'SELECT * FROM actor' --src @sakila_pg
When sq acts on a source, it uses the catalog and schema
specified in the source’s location, or the default catalog and schema if not explicitly specified
in the location. For example, a Postgres source defaults to the public schema.
For some commands, you can override the catalog and/or schema for just that single command invocation.
# Execute SQL query against the active, using the "public" schema in
# the "inventory" catalog.
$ sq sql 'SELECT * FROM products' --src.schema inventory.public
--src.schema accepts a schema, or catalog, or both (delimited by a period).
# Target the "public" schema in the source's default catalog.
$ sq sql 'SELECT * FROM products' --src.schema public
# Target the "public" schema in the "inventory" catalog.
$ sq sql 'SELECT * FROM products' --src.schema inventory.public
# Target the default schema in the source's "inventory" catalog.
$ sq sql 'SELECT * FROM products' --src.schema inventory.
For commands that accept both --src and --src.schema flags, you can combine them:
# Execute SQL query against the @sakila_pg source, using
# the "public" schema in the "inventory" catalog.
$ sq sql 'SELECT * FROM products' --src @sakila_pg --src.schema inventory.public
The CATALOG. form of --src.schema is useful when you don’t
care about specifying the schema (or are just happy to use the default schema),
but you do want to specify the catalog.
For example, this lists the schemas present in @sakila_pg’s default catalog:
$ sq inspect @sakila_pg --schemata
But if we’re instead interested in the schemas of a non-default catalog,
e.g. the inventory catalog, specify CATALOG.:
# List the schemas in the "inventory" catalog of @sakila_pg.
$ sq inspect @sakila_pg --schemata --src.schema=inventory.
Remove
Use sq rm to remove a source (or group of sources).
sq rm only removes the reference to the source
from sq’s configuration.
It doesn’t do anything destructive to the source itself.# Remove a single source.
$ sq rm @sakila_pg
# Remove multiple sources at once.
$ sq rm @sakila_pg @sakila_sqlite
# Remove all sources in the "dev" group.
$ sq rm dev
# Remove a mix of sources and groups.
$ sq rm @prod/customer staging
Move
Use sq mv to move (rename) sources and groups. sq mv works analogously
to the UNIX mv command, where source handles are equivalent to files,
and groups are equivalent to directories.
# Rename a source
$ sq mv @dev/sales @dev/europe/sales
@dev/europe/sales csv sales.csv
# Move a source into a group (the group need not exist beforehand).
$ sq mv @dev/customer dev/europe
@dev/europe/customer csv customer.csv
# Rename a group (and by extension, rename all of the group's sources).
$ sq mv dev/europe dev/europa
dev/europa
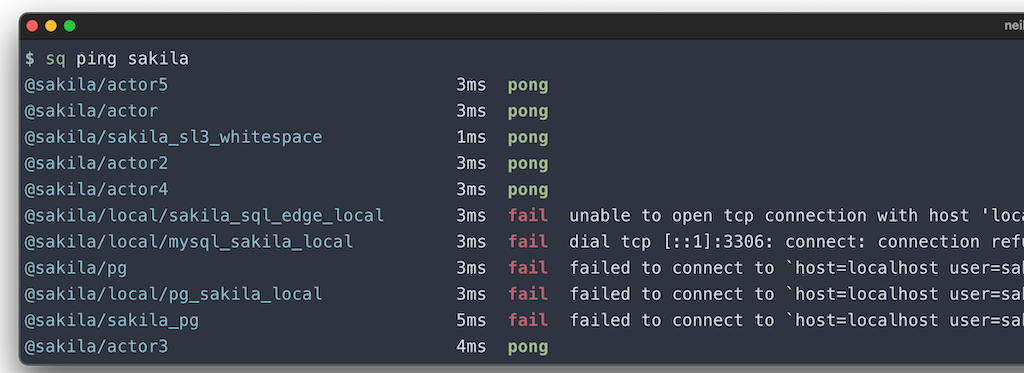
Ping
Use sq ping to check the connection health of your sources.
If invoked without argumetns, sq ping pings the active source. Otherwise, supply
a list of sources or groups to ping.
# Ping the active source.
$ sq ping
# Ping all sources.
$ sq ping /
# Ping @sakila_my, and sources in the "prod" and "staging" groups
$ sq ping @sakila_my prod staging
Groups
If you find yourself dealing with a large number of sources, sq provides a
simple mechanism to structure groups of sources. A typical handle looks like @sales.
But if you use a path structure in the handle like @prod/sales,
sq interprets that prod path as a group.
For example, let’s say you had two databases, customer and sales, and two
environments, dev and prod. You might naively add sources @dev_customer,
@dev_sales, @prod_customer, and @prod_sales.
# This example is using a CSV data source, but it could be postgres, mysql, etc.
$ sq ls
@dev_customer csv customer.csv
@dev_sales csv sales.csv
@prod_customer csv customer.csv
@prod_sales csv sales.csv
Now, if you have dozens (or hundreds) of sources, interacting with them
becomes burdensome. Enter the groups mechanism. Let’s add these sources instead:
@dev/customer, @dev/sales, @prod/customer, @prod/sales.
$ sq ls
@dev/customer csv customer.csv
@dev/sales csv sales.csv
@prod/customer csv customer.csv
@prod/sales csv sales.csv
So, the _ char has been replaced with /… what’s the big difference you ask?
sq interprets /-separated path values in the handle as groups. By default,
you start out in the root group, represented by /. Use sq group to see
the active group:
$ sq group
/
Now, let’s set the active group to dev, and note the different behavior of sq ls:
# Set the active group to "dev".
$ sq group dev
dev
# Now "sq ls" will only list the sources under "dev".
$ sq ls
@dev/customer csv customer.csv
@dev/sales csv sales.csv
You can use sq group / to reset the active group to the root group. But you can
also list the sources in a group without changing the active group:
$ sq ls prod
@prod/customer csv customer.csv
@prod/sales csv sales.csv
If you want to list the groups (as opposed to listing sources), use ls -g:
# Equivalent to "sq ls --group"
$ sq ls -g
/
dev
prod
As you can see above, there are three groups: / (the root group), dev, and prod.
You’re not restricted to one level of grouping. A handle such as @mom_corp/prod/europe/sales
is perfectly valid, and the commands work intuitively. For example, to list all the subgroups
of mom_corp/prod:
$ sq ls -g mom_corp/prod
mom_corp/prod/europe
mom_corp/prod/na
mom_corp/prod/africa
When you have lots of sources and groups, use sq ls -gv (--group --verbose)
to see more detail on the hierarchical structure.
$ sq ls -gv
GROUP SOURCES TOTAL SUBGROUPS TOTAL ACTIVE
/ 4 2 2
dev 2 2 active
prod 2 2
Here’s a real-world example:
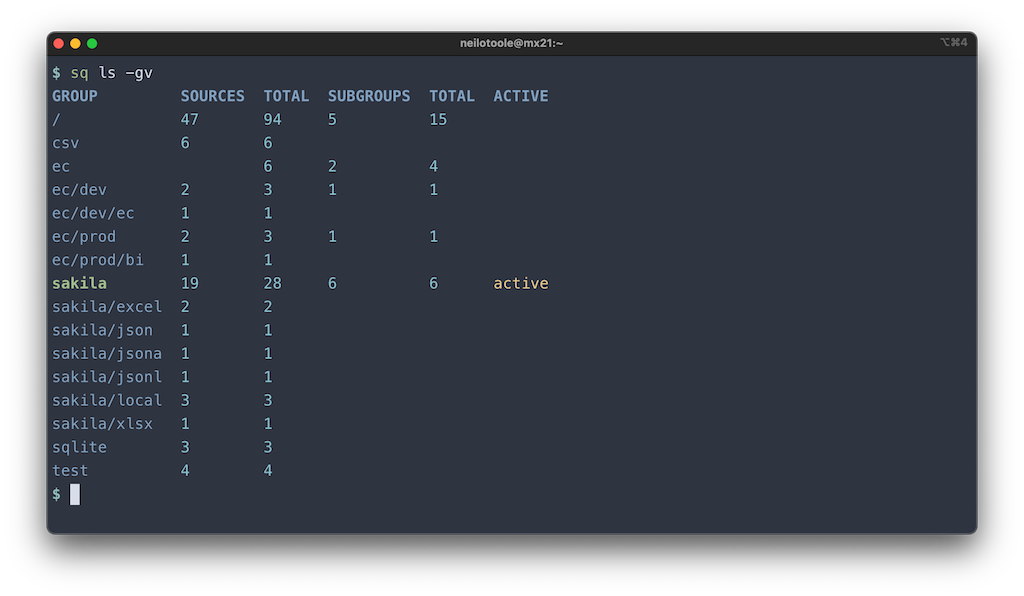
If you want to get really crazy, try the JSON output (sq ls -gj).
You may have noticed by now that groups are implicit. A group “exists” when there exists a source that has the group’s path in the handle. Thus, there is no command to “add a group”. However, you can rename (move) and remove groups.
# Rename a group, i.e. rename all the sources in the group.
$ sq mv old/group new/group
# Remove a group, i.e. remove all the sources in the group.
$ sq rm my/group
These commands are effectively batch operations on the sources in each group.
Document source
A document source is a source backed by a document or file such as CSV or
Excel. Some functionality is not available for document sources.
For example, sq doesn’t provide a mechanism to insert query
results into an Excel file.
A document source’s location can be a local file path, or an HTTP URL. For example:
# Local file path
$ sq add ./actor.csv
# Remote URL
$ sq add https://sq.io/testdata/actor.csv
Ingest
For any document source, sq must first ingest the document data into
a local, hidden “ingest DB” that functions as a cache. This is all managed automatically by sq:
the user doesn’t need to know anything about the ingest DB. Ingest is a generally a one-time operation:
the data is ingested, stored in the ingest DB, and this DB is cached and re-used
the next time sq is invoked. However, if the original source document is modified
on disk, sq detects this, and kicks off a fresh ingest.
Several sq commands can work with stdin input:
$ cat actor.csv | sq '.data | .first_name, .last_name'
$ cat actor.csv | sq inspect
However, note that stdin sources can’t take advantage of the ingest cache, because
the stdin pipe is “anonymous”, and sq can’t do a cache lookup for it. If you’re going to
repeatedly use the same stdin data, you should probably just sq add it.
Download
For remote document sources, sq downloads the source document to a local
file, which is cached and re-used. On subsequent invocations, sq checks
whether the cached file is fresh or stale (possibly making an HTTP request to do so),
and downloads a fresh copy if necessary.
There is currently no option to disable download caching. sq’s cache implementation
is (mostly) compliant with the HTTP spec regarding caching
(RFC 7234) and
is intelligent enough to detect when the remote document has changed, assuming
the remote server follows the HTTP spec. However, if you want to force a
cache invalidation and re-download, you can use sq cache clear @remote_src.
If a remote document is already cached but stale, sq makes an HTTP request
to the server to check whether the document has changed. If the server
is unavailable for some reason, sq emits a warning in the logs,
but continues with the stale cached document.
This is a sort of “Airplane Mode” for remote document sources. You can configure
sq to instead return an error on failed refresh via the
download.refresh.ok-on-err config option.
Cache
sq makes use of an on-disk cache for document sources. Each source has its own cache
in a subdirectory of the main sq cache dir. The cache is used to store
the ingest DB and any downloaded files for remote document sources.
Generally speaking, the user doesn’t need to be concerned with caching mechanics. However, a number of options and commands are available to interact with the cache.
The most relevant of these are sq cache enable,
sq cache disable, and
sq cache clear. Note that the cache can be enabled,
disabled or cleared on a default or per-source basis.
# Clear the cache for the active source
$ sq cache clear @active
# Disable the cache for @sakila_csv
$ sq cache disable @sakila_csv